


Background
In today’s world natural language processing is an important field because human generated content carries a huge amount of information. However these are unstructured data which can be messy and ambiguous thus making NLP challenging. Humans speech with their colloquial usage and social context often complicates the linguistic structure the machine would need to understand the intent of a speech. The rule based approach that was followed earlier in NLP was rigid and often had issues understanding the nuances of human speech. From this perspective the developments in Deep Learning in NLP have led to algorithms that are more flexible and have handled the unstructured and ambiguous data more gracefully than earlier approaches. The approaches are more cognitive and focus on understanding the intent of the speech from several examples fed into the model rather than the interpretation based on rules.
What is transfer learning in NLP?
Now imagine if the algorithms had a way to use the knowledge it gained from solving a task and applying that gained knowledge to solve a related but different problem. Pre-trained language models in NLP help us in doing exactly that and in the field of Deep Learning this idea is known as transfer learning. These models enable data scientists to work on a new problem by providing an existing model they can leverage to build upon to solve a target NLP task. Pre trained models have already proven its effectiveness in the field of Computer Vision. It has been a practice in Computer Vision to train models on the large image corpus such as Image Net that enabled the model to be better at learning the general image features such as curves and lines and then fine tune the model to the specific task. Due to the computational costs involved in training on such a large data set, the introduction of Pre Trained models came in as a boon for those who wanted to build their models accurately but faster and didn’t want to spend time on training on the generic features needed for the task in question.
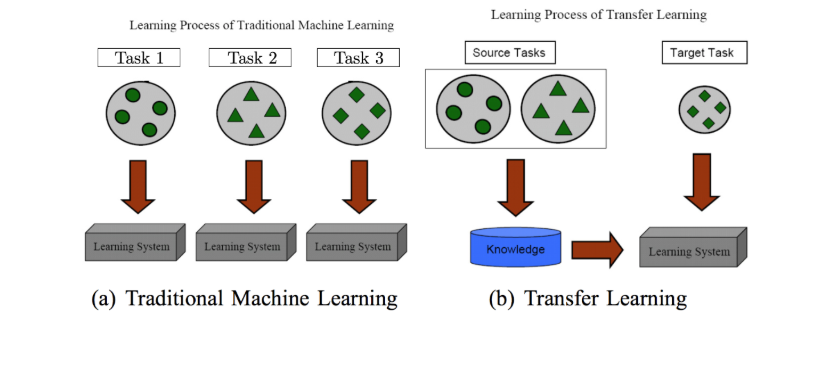
Where can transfer learning be applied?
Applications of Transfer learning in NLP depends mainly on 3 dimensions
- If the source and target settings deal with the same task
- The nature of the source and target domains
- The order of learning for the tasks
Transfer learning are being broadly applied across these NLP tasks, but are not limited to these:
- Text Classification
Example: Spam filtering in emails, Theme based document classification, Sentiment Analysis
- Word Sequence
Example: Chatbots, POS tagging, Named entity recognition
- Text Meaning
Example: Topic modeling, Question answering, Search etc
- Sequence to Sequence
Example: Machine translation, summarization, Q&A systems etc
- Dialog Systems
Example: Chatbots
How does pre trained models help in these NLP tasks?
Pre trained models essentially address the deep learning issues associated with initial training of the model development. Firstly, these language models train on large initial data sets that help capture a language’s intricacies thus overcoming the need for the target task data set to be large enough to train the model on the intricacies of the language. This indirectly helps in preventing overfitting and better generalization performance. Secondly, the computational resource and time for solving a NLP task is reduced as the pre-trained model already understands the intricacies of the language and just needs fine tuning to model the target task. Thirdly, the datasets involved in training these initial models meet industry’s quality standards thus vetting the need for quality check. The model also allows you to achieve the same or better performance even when the target data set has a low amount of labelled data. Lastly, most of these pre trained models are open source and its availability to the industry to build on.
What are some of its business applications?
Considering the benefits associated with transfer learning achieved through pre trained models. Business areas where these pre trained models can improve the performance includes:
- Grouping documents by a specific feature as in Legal discovery
- Enhancing results for finding relevant documents or relevant information on documents – Self Serving Tech Support
- Improving Product response tracking in campaigns through better sentiment analysis of the reviews
- Enhancing customer interactions with chatbots
- Summarizing technical documents or contracts
- Improving community management of online contents
What are the available Open Source Models and Frameworks
Some of the models and frameworks that are open source and available to work with includes:
- ULMFiT ( Universal Language Model Fine-tuning )
- ELMO ( Embeddings from Language Models )
- BERT ( Bidirectional Encoder Representations )
- XLNet
- ERNIE ( Enhanced Representation through kNowledge IntEgration)
- BPT ( Binary Partitioning Transformer)
- T5 ( Text To Text Transfer Transformer )
The above list is not exhaustive and there are many developments in this field. Depending on the need of the business and the target task in question we can always utilize these pre trained models for performing the target NLP task efficiently.
How is the model applied to a target task?
Let us take a look at the application and the architecture of a pre-trained model for a text classification task such as Click Bait Detection using Universal Language Model Fine-tuning (ULMFiT). We can utilize the data for click bait detector problem from Kaggle. This data set consists of labeled articles, where each article consists of a label and body. The target task is to predict whether it is clickbait or article. ULMFiT developed by Jeremy Howard and Sebastian Ruder at its core consist of 3 layer AWD- LSTMs. Their approach consists of three stages:
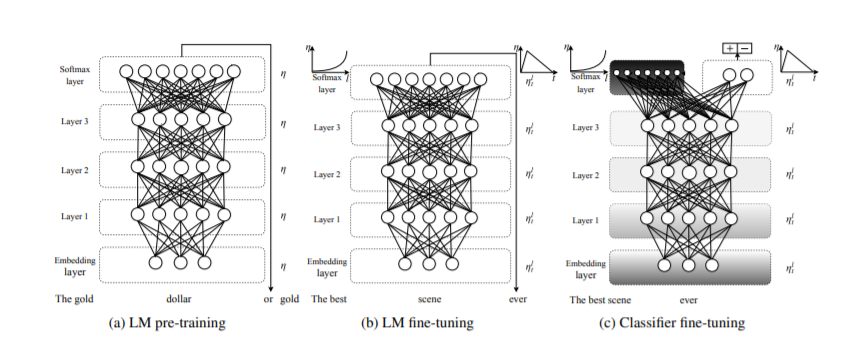
- Language Model Pre Training
In the first stage they trained their initial language model on WikiText-103 data set, which is a large general domain corpus that has more than 100 million tokens. The LM consists of an embedding layer, 3 layer AWD-LSTM and finally a softmax layer. After the pretraining stage the model can predict the next word in a sequence. At this stage the model’s initial layers have been trained on the general features of the language such as the sentence structure. This LM is available to us as the pretrained model via fastai library.
- Language Model Fine Tuning
In the second stage, the LM will be fine tuned on the target dataset i.e in our case the Clickbait data set. The Clickbait data set has a different distribution than the initial LM data set. The entire dataset without labelled data would be the input to the model. Hence fine tuning of the LM will ensure the nuances pertaining to the target data set is also learnt. Here the architecture is similar to the initial LM. The layers will be fine tuned by Discriminative Fine-Tuning with slanted triangular learning rates. Discriminative fine-tuning allows us to tune each layer with different learning rates instead of using the same learning rate for all layers of the model. For adapting its parameters to task-specific features, the model quickly converges to a suitable region of the parameter space in the beginning of training and then refine its parameters. This results in a slanted triangular distribution of learning rates. At this stage the initial layers would have generic information on the language while subsequent layers will have target specific features such as the usage of tenses etc.
- Classifier Fine Tuning
In the final stage, the fine tuned LM’s architecture is modified to include two linear blocks – ReLU and softmax activation. ReLU activation is used in the intermediate layer while the softmax for the last layer. Each block uses batch normalization and dropout. Concat pooling ensures the last hidden state is concatenated with a max-pooled and a mean-pooled representation of the hidden states throughout time. Fine tuning needs to be performed very carefully to ensure the benefits of the LM pre training are not lost. Hence the layers of the model are gradually unfrozen and fine tuned for an epoch starting from the outer softmax layer. This gradual unfreezing and concat pooling ensures the model doesn’t fall prey to catastrophic forgetting. After all the layers have been unfrozen and fine-tuned, the model is ready for predicting the click bait.
Conclusion
Pre-trained models in NLP is definitely a growing research area with improvements to existing models and techniques happening regularly. Pre-trained models currently use fine tuning as a way to transfer learning and build new models. Explorations on other methods that could optimize the model building process is an area where research is progressing towards. Research on models for non English content is also an area of interest for many researchers. Research in these areas will definitely enable data scientists to solve known NLP tasks more efficiently without the overhead of deep learning issues.


