

Introduction :
Natural Language Processing is an artificial intelligence technique that has enabled machines to understand and process human language. This has been achieved with the help of century long research on Computational linguistics, Statistical modelling and recent advancements in machine learning.
In this article we will deep dive into the barriers faced by non-english languages to adopt and utilize the advancements in NLP and the recent developments that are opening up opportunities for us to break these barriers.
MultiLingual Language models will transform the NLP landscape :
Natural Language Processing capabilities have seen tremendous improvements in recent years due to advancements in deep learning algorithms and the invention of transformer based models including BERT, XLNet and ELMO to name a few.
The current NLP capabilities and some of their applications include :
- Machine translation – Translate text in one language to another eg : Google translate
- Sentiment analysis – Ability to extract emotions and moods from text eg : Online review classifiers
- Text to Speech – Transform text to speech and provide voice based interactive assistance. Eg : Alexa
- Content Categorization – Analyze large volume of textual data and develop categories and indexing to enable efficient search and retrieval systems.
A large number of studies are being conducted to fine tune existing models, improve accuracy and develop Human-like NLP capabilities.
With the development of Multilingual language models, all these capabilities can be transferred to the Non English languages. This will provide diversified opportunities for NLP proliferation and to develop business use cases for localizing and personalization of services.
For instance: :
- Consumers will have access to voice assistants and chat bots in their preferred local languages which will increase the reach of business and result in higher customer satisfaction.
- It will be effective in understanding social media sentiments and reviews in non english platforms.
- It will also be much easier to provide localized content to the target audience with significant improvements in machine translation.
NLP advancements in Non English Languages :
Most of the advancements in NLP are biased towards English as a language. There are more than 6000 living languages in the world with the UN recognizing 6 official languages. But NLP techniques are developed primarily in English Language.
The barriers for NLP proliferation in non-English languages can be summarized as follows :
- The amount of research in NLP is highly skewed towards the English language as it is the most preferred language for business and academic communication across the globe.
- Availability of large corpus of digital textual data – which is essential for training and increasing the accuracy of the NLP systems makes English a high resource language.
There is a dire need for NLP advancements in other languages to ensure that the technology benefits non english speaking communities and businesses are able to develop localized applications to reach customers in their preferred languages.
Transfer learning, a tested machine learning technique and pre-trained language models provide promising opportunities to overcome these challenges.
Let us try to get an understanding of these aspects of NLP before we get into the details on the Cross lingual Language models.
Language Models are essential components in Multilingual NLP Tasks:
Language models form the basis for any NLP task. Any cross lingual language model begins with the development of a well-trained language model in the source language. The primary objective of a language model is to predict the next word, given the previous word. The language model in course of its training is able to acquire capabilities that can be applied to other downstream NLP tasks like translation, sentiment analysis, voice recognition etc.. This is because the model is able to understand the semantics – the grammatical structure and rules of the language along with the context – the general understanding of words in different contexts.
Eg :
‘It’s cloudy today’ .
‘ She was at cloud nine’.
The word cloud means different things in the two contexts and a well-trained language model should be able to differentiate between these two and predict words accordingly.
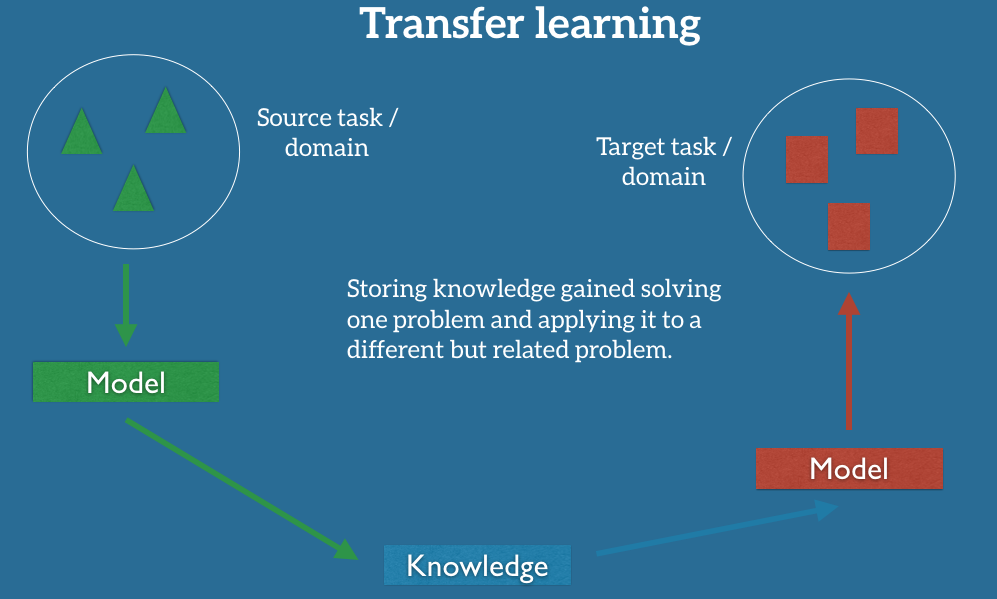
Transfer Learning expedite proliferation of NLP in other languages :
NLP tasks require large amounts of time and effort to achieve the desired objectives and accuracy. Since most of the research is done in English, NLP capabilities can be transferred to other languages with the help of the transfer learning approach.
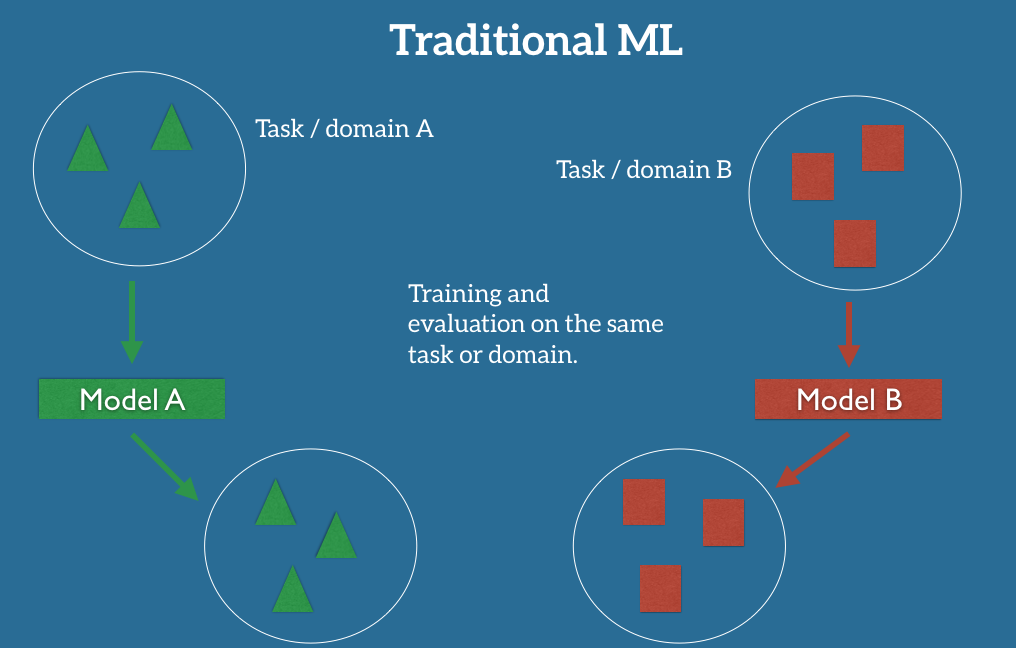
Transfer learning is the process of training a generalised model on a large dataset and fine-tuning this model to perform any downstream tasks. This reduces the time and effort required to train a model from scratch.
In NLP, pretraining enables a language model to capture various aspects of the language, including semantics and context as discussed earlier. This Generalized language model can then be fine tuned to perform downstream tasks like sentiment analysis through the transfer learning approach. This approach was successfully implemented in ULMFiT where the language model pre-trained on WikiText dataset was fine tuned to IMDB dataset. The final classifier trained on 100 labelled data was able to achieve the same level of performance as of an conventional model trained on 10000 labelled data.
Let us now look at how cross lingual language models are developed by the transfer learning approach.
An Overview of Cross Lingual Language Models :
A cross-lingual language model trains on multiple languages simultaneously. Some of the cross lingual language models include:
- mBERT – The multilingual BERT which was developed by Google Research team in June 2019
- XLM – Cross lingual Model developed by Facebook AI which is an improvisation over mBERT
- Multifit – A QRNN based model developed by Fast.Ai that addresses challenges faced by low resource language models
mBERT :
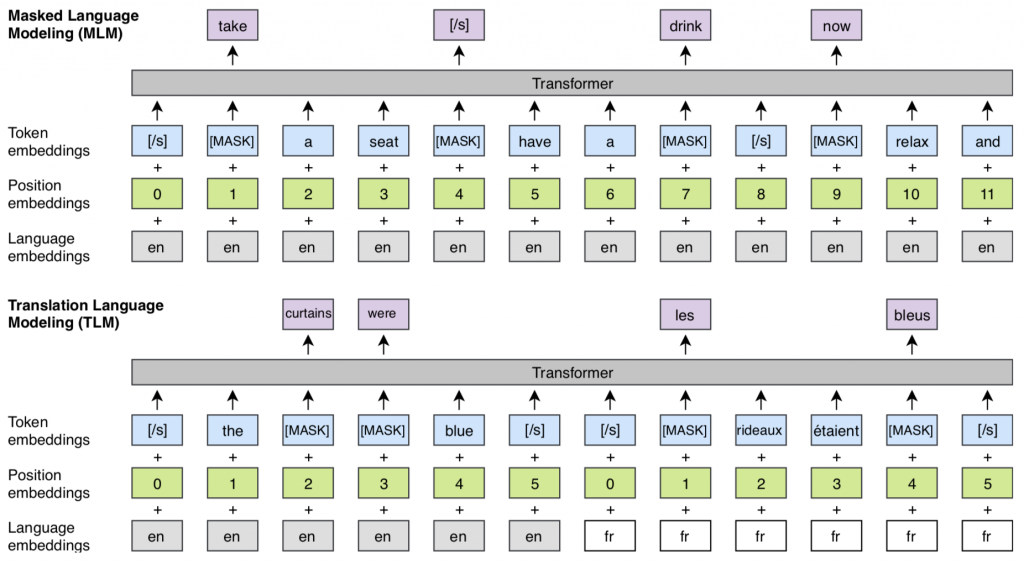
BERT is a transformer based NLP model which is trained to predict a masked word – this is referred to as Masked Language Modelling. BERT is trained with randomly masked input of words/sentences and the model learns to predict the masked word and contiguous sentences in a language. By way of training on a massive dataset BERT produces representations that can be used in downstream NLP tasks like classification.
Multilingual BERT is a similar model trained on the Wikipedia data set of 104 languages.. mBERT trained this way is able to produce representations that work across languages. This is possible due to various linguistic aspects like
- Named entity recognitions – names and nouns do not differ between languages
- Word piece overlaps – same words appearing in different languages
- Structural similarity – the order of the subject, verb and object in sentences
The major drawback of BERT is the under representation of low resource languages – languages which might not have enough parallel datasets for the model to capture the contextual understanding equivalent to English.
XLM :
XLM is a transformer based cross lingual language model which uses Translation Language Modeling (TLM) in addition to MLM. The input is masked in both target and source language and the model is able to learn the context from any of the languages used as input.
MultiFit :
Cross lingual language models are not effective when it comes to low resource languages which do not have the required size of parallel dataset for the language model to train. MultiFiT is an approach that uses QRNN( Quasi Recurrent Neural Network) to overcome the shortcomings of cross lingual language models.In MultFit, the Generalized Language Model is trained on the Wikipedia corpus of the target language and then fine tuned using the available target language datasets.
MultiFit is able to outperform the existing multilingual language models with fine tuning on 100 labelled datasets. MultiFit also outperforms the other methods when all models are fine-tuned on 1000 target language examples.
Zero-shot Transfer with a Cross-lingual Teacher for low resource languages :
The cross lingual language models are efficient for high resource languages that have large parallel dataset that can be leveraged for transferring NLP capabilities from English. But when it comes to low resource languages, they are at a disadvantage and it’s very hard to achieve the expected accuracy with the above methods. The zero shot transfer can provide great advantage in such scenarios.
The Multifit approach can be used to develop a zero shot classifier on the target language by fine-tuning the LM on Predicted labels from a cross lingual model like LASER. As explained in the figure below
- A cross lingual classifier in the source language is fine tuned with target language documents.
- Parallelly a pre-trained LM of the target language is developed from the Wikipedia dataset and fine tuned against the target language documents.
- The pretrained cross lingual classifier and the fine tuned target LM are used to develop a zero shot classifier. This method is significant for a low resource language with limited available digital dataset for which conventional models do not show considerable results.
Conclusion :
Multilingual language models will help in easy proliferation of NLP tasks in all non-English languages. The downstream NLP tasks including text prediction, Chatbots, Classification, Voice assistants and text summarization can be developed in any language without any barriers. It will also improve machine translation capabilities which will democratize access to knowledge and resources for the larger world community.

