


Rethinking data platforms to enable digital transformation: Part 2
In our previous post of the same series, we mulled over various challenges that shape engineering analytics platforms. We looked at multiple user personas that consume data within organizations and their diverse analytical workload requirements. We identified data silos and lack of workload specific compute as core concerns in the contemporary data engineering landscape. Our objective then is to architect a central ground truth that can accommodate any type of compute requirements to serve a business use case. In order to scale the infrastructure and user consumption, we should also infuse accountability and enforce governance into the overall setup. In this blog, we will further analyze the problems in-depth and propose an ideal engineering stack to address data, infrastructure and governance related concerns.
As data is gathered in the ecosystem from disparate sources, it brings with it, four primary challenges – Velocity, Variety, Volume and Veracity. Any analytics infrastructure should be built to handle these four problems. The extent to which those challenges are addressed qualitatively determines the success of the infrastructure. Different businesses focus on addressing different priorities. As organizations mature in their analytics and business processes, they have to invariably address all the four problems at some point. That being said, at the core of all the problems is veracity.
Building a single source of true data
In an urge to build analytics capabilities, different teams tend to curate data from diverse sources, bake in their domain specific pre-processing, filters and post processing, apply rules, analyze and even end up building machine learning models to answer their business priorities. In this process, invariably, different business teams tend to build their version of a “truthful” source and continue to build and benchmark results on their version of “truthful” data. This leads to data fragmentation across different business domains. This fragmentation problem is invisible until a need comes in to unify business processes, collaborate and build data solutions that cuts across different business domains.
All organizations, in an effort to place customer at its heart to drive business and develop processes, have started unifying domains and promote collaboration to build and deliver a 360-degree view of the customer. In that view, there is no scope for fragmented data and unwavering requirement to build a central data repository which would be held as the ground truth for all analytics operations. The idea is to build one converged data store that will hold the ground truth, which will then be able to cater to different streams and demands of business requirements to deliver value.
Origins of a central data repository:
Let’s attempt to define the traits of a central data repository.
| Workload/Compute agnostic for | Metrics Computation, Reporting Ad-hoc Analysis Advanced Analytics Real-time Systems |
| Secure access via | Client specific integrated authentication/authorization |
| Ground truth dataset available as | Latest version of data Cumulative history (Immutable) |
| Optimized for compute and storage as | Columnar Compressed Partitioned |
| Discoverable via | Tagged metadata |
| Systematic refresh via | Configurable inputs |
| Advanced Analytics Workbenches for | At-Scale prototyping Continuous integration and deployment of machine learning models A/B testing and Integration of AI/ML results into application |
| Intuitive summary and ease of use | Statistical summary and Anomaly identification Intuitive interactive visualizations |
Data ecosystem design pattern:
At LatentView Analytics, we work with clients across banking, finance, CPG, energy, retail, healthcare, media, telecom, technology and partner with global academic institutions to build solutions that are state of the art and relevant to business. In order to power the next wave of analytics-driven decision making at scale, we do see a strong need for an organized and well managed data repository for many of our clients. By considering the ideal characteristics of a central data repository discussed above and assessing the analytics maturity of our prospects and clients, we have built a klotski styled ideal data engineering stack that will deliver, manage and run the modern analytical engine to fuel the growth of organizations.
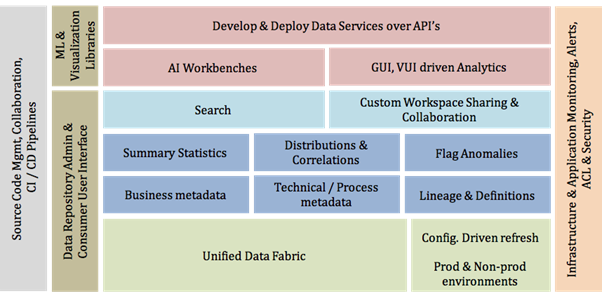
Our approach to engineering an ideal stack depends on the level of analytical maturity within our client organizations. The Analytical Maturity Assessment is custom designed for different business verticals and is very useful to propose the right approach, appropriate technical components and outcome bound priorities based on short and long term strategic goals.
A unified data fabric will be the central data repository that will be periodically refreshed from various internal and external sources. The refresh by design is configuration driven in order to maximize the re-use of code and environment setup. The key aspect to note here is the proactive isolation of production and development environments. This is often overlooked in many data engineering setups and eventually leads to ineffective analysis and incomplete benchmarking. As data ecosystems evolve, richer functionalities are required to support easier adoption. Exposing business and technical metadata makes data discoverable over a search and additional information such as lineage and definitions help build trust between the data infrastructure and data consumers.
In a contemporary set-up, there is a great need for self-serve analytics which is used operationally by thousands of users within an organizations for every day decision making. It is very important in such scenarios for those data hungry users to feed descriptive statistics and intimation about anomalies to help them form a better intuition about the data. It will save hours of analysis by hinting about potential data differences and metric deviations expected in their reports and summary. In addition to statistics about data, it is also very critical to expose infrastructural and operational metrics to analyze and fine tune the performance of the entire ingestion and analysis process.
There are three major data-powered actions that are commanded out of a new age analytics system. They are as follows:
- Advanced Analytics Workbenches for users to prototype approaches at-scale
- Interactive analytics (GUI based, Voice powered and Conversational)
- Data as a service (DaaS) in a secure and scalable fashion
These are precisely the requirements that break the traditional monolithic warehouse. In order to accommodate the same, we have to invest in setting-up a continuous code integration, testing and deployment platform that makes the entire process accountable and manageable at-scale. With an all new set-up and process, the harder problem to handle is rollout and adoption without impacting business continuity. This can be achieved by very closely aligning with the business priorities and involving all the business representatives as part of the design and implementation. There could be steep learning curves involved with respect to user onboarding and technology adoption. This concern can be mitigated by conducting deep-dive and hands-on workshops. Last but not the least, incentivize users by public recognition of adoption, document and promote necessary content and engage by clearly explaining the overall business benefit that the organization derives by moving to a cleaner and scalable engineering analytics stack.


