


Prompt engineering is the latest discipline for developing and optimizing prompts for efficient usage of language models (LMs), including various applications and topics. Prompt engineering helps better understand the capabilities and limitations of large language models (LLMs).
Researchers use prompt engineering to enhance LLMs’ capacity on complex tasks such as question answering and arithmetic reasoning. Developers use prompt engineering to design robust and effective prompting techniques that interface with LLMs and other tools.
What Is an LLM Architecture?
An LLM’s architecture refers to the model’s underlying structure and design principles. An LLM is based on the GPT (Generative Pre-trained Transformer) architecture, specifically the GPT-3.5 model from OpenAI. It is a deep learning model utilizing a transformer neural network.
Transformers are a kind of neural network architecture gaining popularity in natural language processing (NLP) tasks because of their ability to capture contextual relationships in a text. The architecture of an LLM consists of multiple layers, each performing specific tasks in the language processing pipeline, with critical components of the GPT-3.5 architecture.
- Input encoding: The input to an LLM is typically a sequence of tokens (words or subwords) representing the text. These tokens are first converted into numerical embeddings that capture their semantic meaning and positional information.
- Transformer layers: An LLM employs a stack of transformer layers consisting of two sub-layers — a multi-head self-attention mechanism and a feed-forward neural network. The self-attention mechanism ensures that the model weighs the significance of different words in the input sequence. At the same time, the feed-forward network applies non-linear transformations to the attention outputs.
- Attention mechanism: The self-attention mechanism is a critical component of the transformer architecture. It allows the model to capture dependencies between words in a sentence by assigning attention weights to each word based on its relevance to other words. This mechanism enables an LLM to understand the context and meaning of the text.
- Contextual embeddings: As the input sequence passes through the transformer layers, each word’s representation is updated based on the context that is provided by surrounding words. These updated contextual embeddings capture the semantic meaning of the words in the given context.
- Decoding and generation: An LLM can generate text by sampling or selecting words based on the learned probability distributions over the vocabulary. The output is generated word by word, with each word conditioned on previously generated words.
- Training: An LLM is trained using a large corpus of text data, where it learns to predict the next word in a sequence given the previous words. This unsupervised training process helps the model capture the text data’s patterns, grammar, and semantic relationships.
Applications of LLMs
LLMs such as GPT-3.5 are advanced AI systems trained on a large corpus of text data and generate human-like responses to prompts. These models employ deep learning techniques, precisely a type of neural network called a transformer, to process and understand the relationships between words and generate coherent and contextually relevant text. Some of the key characteristics and applications of LLMs include:
- Training on big data
- Contextual understanding
- Natural language generation
- Text completion and generation
- Language translation
- Question answering
- Content summarization
- Personalized recommendations
Examples of Prompts
We discuss examples of using prompts to achieve different tasks and introduce key concepts. Often, the best way to learn concepts is by going through examples. The examples below illustrate how you can use well-crafted prompts to perform different tasks.
Text Summarization
Text summarization is one of the standard tasks in natural language generation. Text summarization can include many different flavors and domains. One of the most promising applications of language models is the ability to summarize articles and concepts into quick and easy-to-read summaries. Let’s try an essential summarization task using prompts.
Let’s say you are interested to learn about antibiotics, you could try a prompt like this:
Prompt:
Explain antibiotics.
Output:
Antibiotics are a type of medication used to treat bacterial infections. They work by killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight the disease. Antibiotics are usually taken orally as pills, capsules, or liquids or sometimes administered intravenously. They are ineffective against viral infections, and misusing them can lead to antibiotic resistance.
Question Answering
One of the best ways to get the model to respond to specific answers is to improve the prompt format. As discussed earlier, a prompt combines everything from instructions, context, and input to output indicators to improve results. While these components are not required, it is good practice as the more specific you are with instruction, the better results you will get. Here is an example of how this would look following a more structured prompt.
Prompt:
Answer the question based on the context below. Keep the answer short and concise. Respond “Unsure about answer” if not sure about the answer.
Context: Teplizumab traces its roots to a New Jersey drug company called Ortho Pharmaceutical. There, scientists generated an early version of the antibody, dubbed OKT3. Sourced initially from mice, the molecule could bind to the surface of T-cells and limit their cell-killing potential. In 1986, it was approved to help prevent organ rejection after kidney transplants, making it the first therapeutic antibody for human use.
Question: What was OKT3 initially sourced from?
Output:
Mice.
Text Classification
So far, you have used simple instructions to perform a task. As a prompt engineer, you must improve at providing better instructions. But that’s not all! You will also find that for more complex use cases, just providing instructions won’t be enough. You need to think more about the context and the different elements you can use in a prompt. Other elements you can provide are input data or examples. Let’s try to demonstrate this by providing an example of text classification.
Prompt:
Classify the text into neutral, negative, or positive. Text: I think the food was okay. Sentiment:
Output:
Neutral
Your instruction was to classify the text, and the model responded with “Neutral,” which is correct. Nothing is wrong with this response, but let’s say that you need the model to give the label in the exact format you want. So instead of “Neutral,” you want it to return to neutral. How do you achieve this? There are different ways to do this. You care about specificity here, so the more information you can provide the prompt, the better the results.
Conversation
Perhaps one of the more interesting things you can achieve with prompt engineering is instructing the LLM system on how to behave, its intent, and its identity. This is particularly useful when building conversational systems like customer service chatbots.
For instance, let’s create a conversational system to generate more technical and scientific responses to questions. Note how you are explicitly telling it how to behave through the instruction. This is sometimes referred to as role prompting.
Prompt:
The following is a conversation with an AI research assistant. The assistant’s tone is technical and scientific.
Human: Hello, who are you?
AI: Greetings! I am an AI research assistant. How can I help you today?
Human: Can you tell me about the creation of black holes?
Code Generation
One application where LLMs are quite effective is code generation. Co-pilot is an excellent example of this. There are a vast number of code-generation tasks you can perform with clever prompts. Let’s look at a few examples below.
First, let’s try a simple program that greets the user.
Prompt:
/*Ask the user for their name and say “Hello”*/
Output:
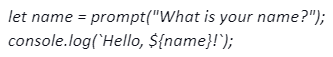
Notice that you didn’t even need to specify the language to use.
Let’s switch levels a bit. The example below shows how powerful LLMs can be with more effort in designing the prompts.
Prompt:
“””Table departments, columns = [DepartmentId, DepartmentName]
Table students, columns = [DepartmentId, StudentId, StudentName]
Create a MySQL query for all students in the Computer Science Department”””
Output:
This is highly impressive. In this case, you provided data about the database schema and asked it to generate a valid MySQL query.
Conclusion
Prompt engineering has opened new possibilities for NLP applications, including content generation, dialogue systems, virtual assistants, language translation, and more. These advancements continue to shape the language understanding and generation field, with ongoing research and development focused on improving capabilities and addressing the challenges associated with these technologies.

